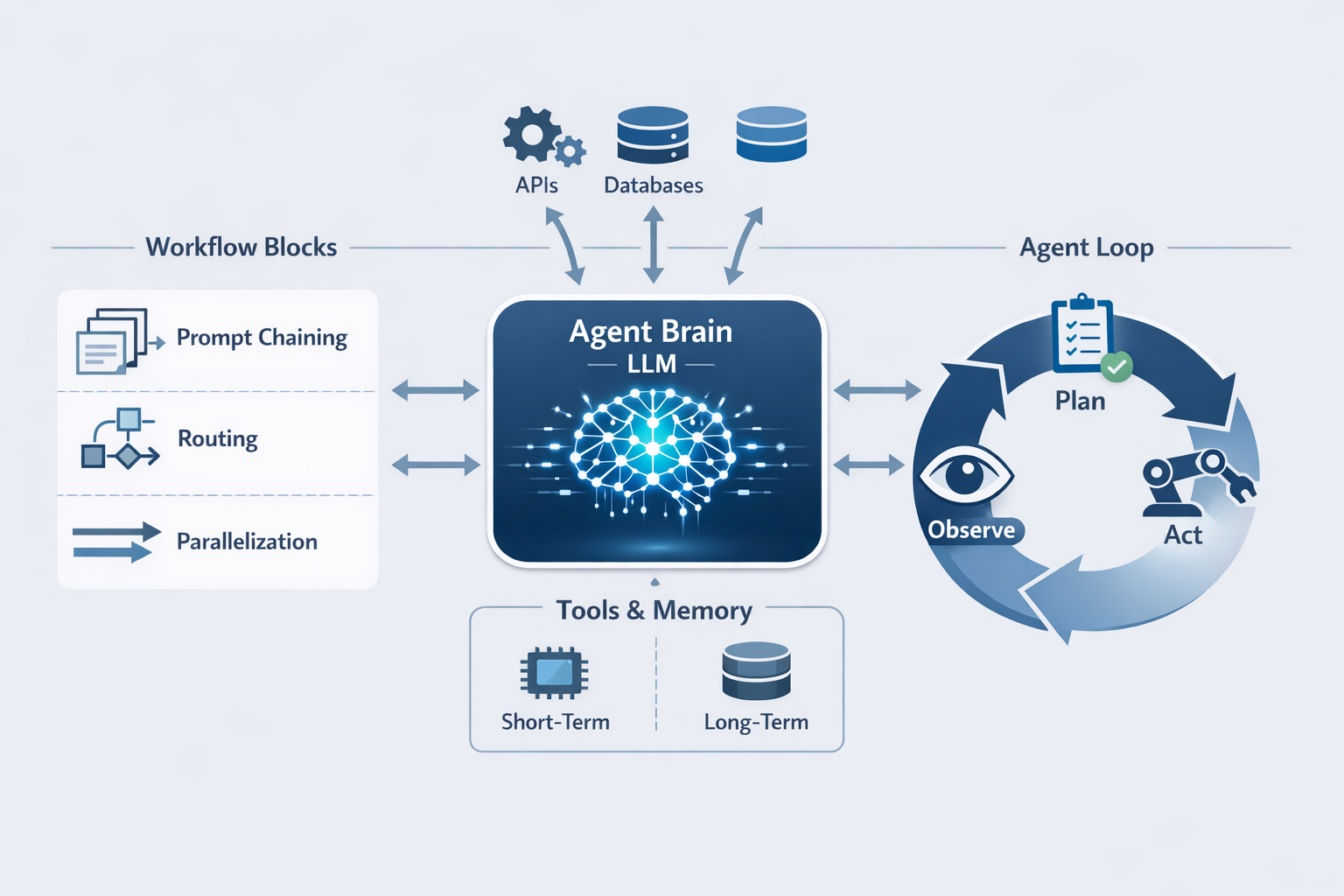
이번 노트북에서는 Anthropic의 연구 자료 Building Effective Agents를 기반으로 에이전트 시스템의 핵심 개념과 구축 패턴을 학습합니다.
개요
| 주제 | 내용 |
|---|---|
| 에이전트 정의 | 워크플로우 vs 에이전트의 차이 |
| 핵심 빌딩 블록 | Augmented LLM (검색, 도구, 메모리) |
| 워크플로우 패턴 | 5가지 기본 패턴 |
| 자율 에이전트 | 독립적으로 작동하는 에이전트 |
| 도구 설계 | 효과적인 도구 인터페이스 설계 |
학습 목표
- 에이전트와 워크플로우의 차이점 이해하기
- 5가지 에이전트 워크플로우 패턴 습득하기
- 언제 에이전트를 사용해야 하는지 판단하기
- 효과적인 도구 설계 원칙 익히기
핵심 철학
"가장 성공적인 구현들은 복잡한 프레임워크나 특수 라이브러리를 사용하지 않았습니다. 대신, 단순하고 조합 가능한 패턴으로 구축되었습니다." — Anthropic
원칙: 단순함에서 시작하고, 복잡성은 명확한 개선이 있을 때만 추가합니다.
1. 에이전트 시스템 정의
에이전트 시스템은 크게 두 가지로 구분됩니다:
워크플로우 (Workflows)
- LLM과 도구가 미리 정의된 코드 경로를 통해 작동
- 단계가 사전에 결정됨
- 예측 가능하고 제어하기 쉬움
에이전트 (Agents)
- LLM이 자체 프로세스와 도구 사용을 동적으로 지시
- 작업 실행에 대한 제어권을 유지
- 더 유연하지만 복잡함
┌─────────────────────────────────────────────────────────────────┐
│ 에이전트 시스템 │
├─────────────────────────────┬───────────────────────────────────┤
│ 워크플로우 │ 에이전트 │
├─────────────────────────────┼───────────────────────────────────┤
│ • 미리 정의된 단계 │ • 동적으로 결정되는 단계 │
│ • 고정된 코드 경로 │ • LLM이 경로 선택 │
│ • 예측 가능 │ • 유연하지만 덜 예측 가능 │
│ • 낮은 지연 시간/비용 │ • 높은 지연 시간/비용 │
└─────────────────────────────┴───────────────────────────────────┘
언제 에이전트를 사용해야 할까?
| 상황 | 권장 접근법 |
|---|---|
| 단계 수 예측 가능 | 워크플로우 |
| 고정 경로 하드코딩 가능 | 워크플로우 |
| 개방형 문제 | 에이전트 |
| 단계 수 예측 불가 | 에이전트 |
중요: 많은 애플리케이션에서 검색과 인컨텍스트 예제를 활용한 단일 LLM 호출 최적화만으로도 충분합니다.
에이전트는 더 나은 성능을 위해 지연 시간과 비용을 교환합니다.
2. 핵심 빌딩 블록: Augmented LLM
에이전트의 기초는 검색(Retrieval), 도구(Tools), 메모리(Memory) 로 강화된 LLM입니다.
┌─────────────────┐
│ Augmented │
│ LLM │
└────────┬────────┘
│
┌─────────────────┼─────────────────┐
│ │ │
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ Retrieval│ │ Tools │ │ Memory │
│ (RAG) │ │ (API 등) │ │ (상태) │
└──────────┘ └──────────┘ └──────────┘
│ │ │
▼ ▼ ▼
벡터 DB에서 외부 서비스 이전 대화/
관련 정보 검색 호출 및 실행 컨텍스트 유지
Model Context Protocol (MCP): 서드파티 도구를 최소한의 구현 오버헤드로 통합할 수 있는 프로토콜입니다.
# 기본 환경 설정
import os
from dotenv import load_dotenv
load_dotenv(override=True)
api_key = os.getenv('OPENAI_API_KEY')
if api_key:
print("API key found.")
else:
print("No API key was found")from openai import OpenAI
client = OpenAI()
def call_llm(messages, model="gpt-4o-mini"):
"""기본 LLM 호출 함수"""
response = client.chat.completions.create(
model=model,
messages=messages
)
return response.choices[0].message.content3. 워크플로우 패턴
Anthropic은 5가지 핵심 워크플로우 패턴을 제시합니다:
┌────────────────────────────────────────────────────────────────────────┐
│ 5가지 워크플로우 패턴 │
├────────────────────────────────────────────────────────────────────────┤
│ 1. Prompt Chaining │ 순차적 LLM 호출 체인 │
│ 2. Routing │ 입력 분류 후 전문화된 경로로 분기 │
│ 3. Parallelization │ 병렬 실행 후 결과 집계 │
│ 4. Orchestrator-Workers│ 중앙 LLM이 작업 분배 및 종합 │
│ 5. Evaluator-Optimizer │ 생성-평가 반복 루프 │
└────────────────────────────────────────────────────────────────────────┘
3.1 Prompt Chaining (프롬프트 체이닝)
작업을 순차적 단계로 분해하여 각 LLM 호출이 이전 출력을 처리합니다.
┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐
│ 입력 │────▶│ LLM 1 │────▶│ LLM 2 │────▶│ 출력 │
└─────────┘ └────┬────┘ └────┬────┘ └─────────┘
│ │
▼ ▼
┌─────────┐ ┌─────────┐
│ Gate │ │ Gate │
│ (검증) │ │ (검증) │
└─────────┘ └─────────┘
사용 사례:
- 마케팅 카피 생성 → 번역
- 문서 개요 작성 → 전체 문서 작성
# Prompt Chaining 예제: 글 작성 → 요약 → 번역
def prompt_chaining_example(topic):
"""프롬프트 체이닝: 주제 → 글 작성 → 요약 → 영어 번역"""
# Step 1: 주제에 대한 글 작성
step1_messages = [
{"role": "system", "content": "당신은 기술 블로그 작가입니다."},
{"role": "user", "content": f"{topic}에 대해 3문장으로 설명해주세요."}
]
article = call_llm(step1_messages)
print(f"[Step 1] 글 작성:\n{article}\n")
# Gate: 글이 충분히 작성되었는지 확인 (프로그래매틱 검증)
if len(article) < 50:
return "Error: 글이 너무 짧습니다."
# Step 2: 요약
step2_messages = [
{"role": "system", "content": "당신은 요약 전문가입니다."},
{"role": "user", "content": f"다음 글을 한 문장으로 요약해주세요:\n\n{article}"}
]
summary = call_llm(step2_messages)
print(f"[Step 2] 요약:\n{summary}\n")
# Step 3: 영어 번역
step3_messages = [
{"role": "system", "content": "You are a professional translator."},
{"role": "user", "content": f"Translate this to English:\n\n{summary}"}
]
translation = call_llm(step3_messages)
print(f"[Step 3] 번역:\n{translation}")
return translation
# 실행
result = prompt_chaining_example("Large Language Model")3.2 Routing (라우팅)
입력을 분류하고 전문화된 다운스트림 작업으로 전달합니다.
┌─────────────┐
│ 입력 │
└──────┬──────┘
│
▼
┌─────────────┐
│ 분류기 │
│ LLM │
└──────┬──────┘
│
┌─────────────────┼─────────────────┐
│ │ │
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ 카테고리 A│ │ 카테고리 B│ │ 카테고리 C│
│ 전문 처리 │ │ 전문 처리 │ │ 전문 처리 │
└──────────┘ └──────────┘ └──────────┘
사용 사례:
- 고객 서비스 쿼리 분류 (환불/배송/기술지원)
- 간단한 쿼리 → 효율적 모델, 복잡한 쿼리 → 고성능 모델
# Routing 예제: 고객 문의 분류 및 라우팅
def classify_query(query):
"""쿼리를 분류하는 라우터"""
messages = [
{"role": "system", "content": """고객 문의를 분류해주세요.
카테고리: REFUND, SHIPPING, TECHNICAL, GENERAL
카테고리만 대문자로 출력하세요."""},
{"role": "user", "content": query}
]
return call_llm(messages).strip()
def handle_refund(query):
return "[환불팀] 환불 정책을 확인 중입니다..."
def handle_shipping(query):
return "[배송팀] 배송 현황을 조회합니다..."
def handle_technical(query):
return "[기술지원팀] 기술 문제 해결을 도와드립니다..."
def handle_general(query):
return "[일반상담] 문의해 주셔서 감사합니다..."
def routing_example(query):
"""라우팅 패턴 구현"""
# Step 1: 분류
category = classify_query(query)
print(f"입력: {query}")
print(f"분류 결과: {category}")
# Step 2: 적절한 핸들러로 라우팅
handlers = {
"REFUND": handle_refund,
"SHIPPING": handle_shipping,
"TECHNICAL": handle_technical,
"GENERAL": handle_general
}
handler = handlers.get(category, handle_general)
result = handler(query)
print(f"처리 결과: {result}")
return result
# 테스트
print("=" * 50)
routing_example("주문한 상품이 아직 도착하지 않았어요")
print("\n" + "=" * 50)
routing_example("환불 받고 싶습니다")
print("\n" + "=" * 50)
routing_example("앱이 자꾸 멈춰요")3.3 Parallelization (병렬화)
LLM 작업을 동시에 실행하고 결과를 집계합니다.
두 가지 변형:
┌────────────────────────────────────────────────────────────────┐
│ Sectioning (분할) │
│ │
│ ┌─────────┐ │
│ │ 입력 │ │
│ └────┬────┘ │
│ ┌───────────────┼───────────────┐ │
│ ▼ ▼ ▼ │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ 작업 A │ │ 작업 B │ │ 작업 C │ │
│ │ (분석) │ │ (검증) │ │ (평가) │ │
│ └────┬────┘ └────┬────┘ └────┬────┘ │
│ └───────────────┼───────────────┘ │
│ ▼ │
│ ┌─────────┐ │
│ │ 집계 │ │
│ └─────────┘ │
└────────────────────────────────────────────────────────────────┘
┌────────────────────────────────────────────────────────────────┐
│ Voting (투표) │
│ │
│ ┌─────────┐ │
│ │ 입력 │ │
│ └────┬────┘ │
│ ┌───────────────┼───────────────┐ │
│ ▼ ▼ ▼ │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ 동일한 │ │ 동일한 │ │ 동일한 │ │
│ │ 작업 │ │ 작업 │ │ 작업 │ │
│ └────┬────┘ └────┬────┘ └────┬────┘ │
│ └───────────────┼───────────────┘ │
│ ▼ │
│ ┌───────────┐ │
│ │ 다수결/ │ │
│ │ 최선선택 │ │
│ └───────────┘ │
└────────────────────────────────────────────────────────────────┘
사용 사례:
- Sectioning: 가드레일을 별도 LLM 인스턴스에서 실행, 여러 측면의 성능 평가
- Voting: 코드 취약점 리뷰, 콘텐츠 적절성 평가
import concurrent.futures
# Parallelization 예제 1: Sectioning (분할)
def analyze_sentiment(text):
messages = [
{"role": "system", "content": "텍스트의 감정을 분석하세요. (긍정/부정/중립)"},
{"role": "user", "content": text}
]
return f"감정: {call_llm(messages)}"
def extract_keywords(text):
messages = [
{"role": "system", "content": "핵심 키워드 3개를 추출하세요."},
{"role": "user", "content": text}
]
return f"키워드: {call_llm(messages)}"
def summarize_text(text):
messages = [
{"role": "system", "content": "한 문장으로 요약하세요."},
{"role": "user", "content": text}
]
return f"요약: {call_llm(messages)}"
def parallel_sectioning(text):
"""Sectioning: 서로 다른 분석을 병렬 실행"""
print(f"입력 텍스트: {text}\n")
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
futures = {
executor.submit(analyze_sentiment, text): "감정분석",
executor.submit(extract_keywords, text): "키워드추출",
executor.submit(summarize_text, text): "요약"
}
results = []
for future in concurrent.futures.as_completed(futures):
task_name = futures[future]
result = future.result()
print(f"[{task_name}] {result}")
results.append(result)
return results
# 실행
sample_text = "오늘 새로 출시된 AI 서비스를 사용해봤는데, 정말 놀라운 성능이었습니다. 다만 가격이 조금 비싼 것 같아요."
parallel_sectioning(sample_text)# Parallelization 예제 2: Voting (투표)
def voting_example(question):
"""Voting: 동일한 질문을 여러 번 실행하여 다양한 답변 수집"""
print(f"질문: {question}\n")
def get_answer(attempt):
messages = [
{"role": "system", "content": "창의적인 답변을 해주세요."},
{"role": "user", "content": question}
]
return call_llm(messages)
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
futures = [executor.submit(get_answer, i) for i in range(3)]
answers = [f.result() for f in concurrent.futures.as_completed(futures)]
print("수집된 답변들:")
for i, answer in enumerate(answers, 1):
print(f"\n[답변 {i}]\n{answer[:200]}...")
return answers
# 실행
voting_example("AI의 미래에 대해 어떻게 생각하시나요?")3.4 Orchestrator-Workers (오케스트레이터-워커)
중앙 LLM이 동적으로 작업을 분해하고, 워커에게 위임한 후, 결과를 종합합니다.
┌──────────────────┐
│ 입력 │
└────────┬─────────┘
│
▼
┌──────────────────────────────┐
│ Orchestrator │
│ (작업 분해 & 할당) │
└──────────────┬───────────────┘
│
┌───────────────────┼───────────────────┐
│ │ │
▼ ▼ ▼
┌───────────┐ ┌───────────┐ ┌───────────┐
│ Worker 1 │ │ Worker 2 │ │ Worker 3 │
│ (하위작업)│ │ (하위작업)│ │ (하위작업)│
└─────┬─────┘ └─────┬─────┘ └─────┬─────┘
│ │ │
└───────────────────┼───────────────────┘
│
▼
┌──────────────────────────────┐
│ Orchestrator │
│ (결과 종합) │
└──────────────────────────────┘
병렬화와의 차이점: 하위 작업이 사전 정의되지 않고, 오케스트레이터가 입력에 따라 동적으로 결정합니다.
사용 사례:
- 여러 파일을 수정하는 복잡한 코딩 작업
- 여러 소스에서 정보를 수집하는 검색 작업
import json
# Orchestrator-Workers 예제: 복잡한 질문 분해
def orchestrate_task(complex_question):
"""오케스트레이터: 복잡한 질문을 하위 질문으로 분해"""
# Step 1: 오케스트레이터가 작업 분해
decompose_messages = [
{"role": "system", "content": """복잡한 질문을 2-3개의 간단한 하위 질문으로 분해하세요.
JSON 형식으로 출력하세요: {"subtasks": ["질문1", "질문2", "질문3"]}"""},
{"role": "user", "content": complex_question}
]
decomposed = call_llm(decompose_messages)
print(f"[Orchestrator] 작업 분해:\n{decomposed}\n")
# JSON 파싱
try:
subtasks = json.loads(decomposed)["subtasks"]
except:
subtasks = [complex_question] # 파싱 실패시 원본 사용
# Step 2: 워커들이 하위 작업 처리
worker_results = []
for i, subtask in enumerate(subtasks, 1):
worker_messages = [
{"role": "system", "content": "질문에 간단히 답하세요."},
{"role": "user", "content": subtask}
]
result = call_llm(worker_messages)
print(f"[Worker {i}] {subtask}")
print(f" → {result[:150]}...\n")
worker_results.append({"question": subtask, "answer": result})
# Step 3: 오케스트레이터가 결과 종합
synthesize_messages = [
{"role": "system", "content": "하위 질문들의 답변을 종합하여 최종 답변을 작성하세요."},
{"role": "user", "content": f"""원래 질문: {complex_question}
하위 답변들:
{json.dumps(worker_results, ensure_ascii=False, indent=2)}
종합 답변을 작성하세요."""}
]
final_answer = call_llm(synthesize_messages)
print(f"[Orchestrator] 최종 답변:\n{final_answer}")
return final_answer
# 실행
complex_q = "AI가 교육 분야에 미치는 영향과 이에 따른 교사의 역할 변화, 그리고 발생할 수 있는 윤리적 문제는 무엇인가요?"
orchestrate_task(complex_q)3.5 Evaluator-Optimizer (평가자-최적화자)
하나의 LLM이 응답을 생성하고, 다른 LLM이 평가 피드백을 제공하는 반복 루프입니다.
┌──────────────────┐
│ 입력 │
└────────┬─────────┘
│
▼
┌──────────────────────────────┐
│ Generator │
│ (응답 생성) │◀─────────────┐
└──────────────┬───────────────┘ │
│ │
▼ │
┌──────────────────────────────┐ │
│ Evaluator │ │
│ (품질 평가) │ │
└──────────────┬───────────────┘ │
│ │
┌───────┴───────┐ │
▼ ▼ │
┌──────────┐ ┌──────────┐ │
│ Pass │ │ Fail │────────────────┘
│ (통과) │ │ (재시도) │ 피드백 전달
└────┬─────┘ └──────────┘
│
▼
┌──────────────────┐
│ 최종 출력 │
└──────────────────┘
사용 사례:
- 문학 번역 품질 개선
- 여러 라운드의 연구가 필요한 복잡한 검색
# Evaluator-Optimizer 예제: 글쓰기 품질 개선
def evaluator_optimizer_example(topic, max_iterations=3):
"""평가자-최적화자: 글 작성 후 평가를 통한 반복 개선"""
# 초기 글 생성
generator_messages = [
{"role": "system", "content": "주어진 주제에 대해 짧은 글(3-4문장)을 작성하세요."},
{"role": "user", "content": f"주제: {topic}"}
]
current_text = call_llm(generator_messages)
for iteration in range(max_iterations):
print(f"\n{'='*50}")
print(f"[Iteration {iteration + 1}]")
print(f"현재 글:\n{current_text}")
# 평가
evaluator_messages = [
{"role": "system", "content": """글의 품질을 평가하세요.
기준: 명확성, 논리성, 흥미도
JSON 형식으로 출력: {"score": 1-10, "passed": true/false, "feedback": "개선점"}
score가 8 이상이면 passed: true"""},
{"role": "user", "content": current_text}
]
evaluation = call_llm(evaluator_messages)
print(f"\n평가 결과: {evaluation}")
try:
eval_data = json.loads(evaluation)
if eval_data.get("passed", False):
print(f"\n✓ 품질 기준 통과! (점수: {eval_data.get('score', 'N/A')})")
return current_text
feedback = eval_data.get("feedback", "더 개선해주세요.")
except:
feedback = "더 명확하고 흥미롭게 개선해주세요."
# 피드백 기반 개선
improve_messages = [
{"role": "system", "content": "피드백을 반영하여 글을 개선하세요."},
{"role": "user", "content": f"원본 글:\n{current_text}\n\n피드백:\n{feedback}\n\n개선된 글을 작성하세요."}
]
current_text = call_llm(improve_messages)
print(f"\n최대 반복 횟수 도달. 최종 결과 반환.")
return current_text
# 실행
final_text = evaluator_optimizer_example("인공지능과 인간의 협업")4. 자율 에이전트 (Autonomous Agents)
자율 에이전트는 명확한 작업 지시를 받은 후 독립적으로 작동합니다.
┌─────────────────────────────────────────────────────────────────┐
│ 자율 에이전트 루프 │
│ │
│ ┌─────────────┐ │
│ │ 사용자 │ │
│ │ 작업지시 │ │
│ └──────┬──────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────┐ │
│ │ │ │
│ │ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ │
│ │ │ 계획 │───▶│ 실행 │───▶│ 관찰 │ │ │
│ │ │(Plan) │ │(Action) │ │(Observe)│ │ │
│ │ └─────────┘ └─────────┘ └────┬────┘ │ │
│ │ ▲ │ │ │
│ │ └──────────────────────────────┘ │ │
│ │ 피드백 루프 │ │
│ └─────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────┐ │
│ │ 종료 조건 │ (완료, 최대 반복, 장애물) │
│ └─────────────┘ │
└─────────────────────────────────────────────────────────────────┘
핵심 특징
- 환경에서 실제 정보 획득: 각 단계에서 도구 호출 결과나 코드 실행 결과로 진행 상황 평가
- 체크포인트: 장애물을 만나거나 중요 시점에서 사람의 피드백 요청 가능
- 종료 조건: 최대 반복 횟수 등으로 제어 유지
구현 실제
"일반적으로 루프 내에서 환경 피드백을 기반으로 도구를 사용하는 LLM일 뿐입니다."
에이전트가 정교한 작업을 처리하더라도, 구현은 종종 단순합니다.
# 간단한 자율 에이전트 예제
class SimpleAgent:
"""도구를 사용하는 간단한 자율 에이전트"""
def __init__(self, max_iterations=5):
self.max_iterations = max_iterations
self.tools = {
"calculate": self.calculate,
"search": self.search,
"done": self.done
}
self.is_done = False
self.final_answer = None
def calculate(self, expression):
"""간단한 계산 도구"""
try:
result = eval(expression)
return f"계산 결과: {expression} = {result}"
except:
return f"계산 오류: {expression}"
def search(self, query):
"""시뮬레이션된 검색 도구"""
# 실제로는 웹 검색 API 호출
return f"검색 결과: '{query}'에 대한 정보를 찾았습니다."
def done(self, answer):
"""작업 완료 도구"""
self.is_done = True
self.final_answer = answer
return f"작업 완료: {answer}"
def decide_action(self, task, history):
"""다음 행동 결정"""
messages = [
{"role": "system", "content": f"""당신은 도구를 사용하는 에이전트입니다.
사용 가능한 도구:
- calculate(expression): 수학 계산
- search(query): 정보 검색
- done(answer): 최종 답변 제출
JSON 형식으로 응답: {{"tool": "도구명", "argument": "인자"}}"""},
{"role": "user", "content": f"작업: {task}\n\n이전 기록:\n{history}\n\n다음 행동을 결정하세요."}
]
return call_llm(messages)
def run(self, task):
"""에이전트 실행"""
print(f"[에이전트 시작] 작업: {task}\n")
history = []
for i in range(self.max_iterations):
if self.is_done:
break
print(f"--- 반복 {i + 1} ---")
# 행동 결정
action_str = self.decide_action(task, "\n".join(history))
print(f"결정: {action_str}")
# JSON 파싱 및 도구 실행
try:
action = json.loads(action_str)
tool_name = action.get("tool", "done")
argument = action.get("argument", "")
if tool_name in self.tools:
result = self.tools[tool_name](argument)
print(f"실행 결과: {result}\n")
history.append(f"행동: {tool_name}({argument}) → {result}")
else:
history.append(f"알 수 없는 도구: {tool_name}")
except Exception as e:
history.append(f"오류: {str(e)}")
if not self.is_done:
print("[최대 반복 도달]")
print(f"\n[최종 답변] {self.final_answer}")
return self.final_answer
# 실행
agent = SimpleAgent(max_iterations=5)
agent.run("100 + 200 + 300의 결과를 계산해주세요.")5. 도구 설계 원칙
"도구 설계에 프롬프트 엔지니어링과 동일한 노력을 투자하세요."
Anthropic은 SWE-bench 작업에서 전체 프롬프트보다 도구 최적화에 더 많은 시간을 투자했다고 밝혔습니다.
┌─────────────────────────────────────────────────────────────────┐
│ 도구 설계 원칙 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 1. 충분한 토큰 제공 │
│ → 모델이 제약되기 전에 추론할 수 있는 충분한 토큰 제공 │
│ │
│ 2. 자연스러운 형식 │
│ → 인터넷에서 자연스럽게 발생하는 텍스트와 일치하는 형식 유지 │
│ │
│ 3. 포맷팅 오버헤드 제거 │
│ → 줄 번호 세기, 문자열 이스케이프 같은 부담 제거 │
│ │
│ 4. Poka-yoke 원칙 │
│ → 실수하기 어렵게 도구 설계 │
│ → 예: 절대 경로 요구로 상대 경로 오류 방지 │
│ │
└─────────────────────────────────────────────────────────────────┘
Agent-Computer Interface (ACI)
사람을 위한 UI/UX가 중요하듯, 에이전트를 위한 도구 인터페이스 설계가 핵심입니다.
- 명확하고 철저한 도구 문서화
- 에이전트 관점에서 도구 테스트
- 일반적인 오류 패턴 방지
# 좋은 도구 설계 vs 나쁜 도구 설계 예제
# ❌ 나쁜 예: 모호한 도구 정의
bad_tool = {
"name": "file_op",
"description": "파일 작업을 수행합니다.",
"parameters": {
"path": "파일 경로",
"action": "작업 유형"
}
}
# ✅ 좋은 예: 명확하고 상세한 도구 정의
good_tool = {
"name": "read_file",
"description": """지정된 파일의 내용을 읽어 반환합니다.
반환값: 파일의 전체 내용 (문자열)
오류: 파일이 없으면 FileNotFoundError 메시지 반환""",
"parameters": {
"absolute_path": {
"type": "string",
"description": "파일의 절대 경로. 반드시 /로 시작해야 합니다. 예: /home/user/document.txt",
"required": True
},
"encoding": {
"type": "string",
"description": "파일 인코딩. 기본값: utf-8",
"default": "utf-8"
}
}
}
print("나쁜 도구 정의:")
print(json.dumps(bad_tool, indent=2, ensure_ascii=False))
print("\n" + "="*50 + "\n")
print("좋은 도구 정의:")
print(json.dumps(good_tool, indent=2, ensure_ascii=False))6. 프레임워크 가이드
다양한 에이전트 프레임워크가 있지만, Anthropic의 권장사항:
"개발자들은 LLM API를 직접 사용하는 것부터 시작하세요. 많은 패턴이 몇 줄의 코드로 구현될 수 있습니다."
주요 프레임워크
| 프레임워크 | 설명 |
|---|---|
| Claude Agent SDK | Anthropic 공식 에이전트 SDK |
| LangChain/LangGraph | 인기 있는 LLM 애플리케이션 프레임워크 |
| AWS Strands | AWS의 에이전트 프레임워크 |
| Rivet | 비주얼 에이전트 빌더 |
| Vellum | 엔터프라이즈 LLM 플랫폼 |
주의사항
- 프레임워크 사용 시 내부 코드를 이해해야 함
- 숨겨진 구현에 대한 잘못된 가정이 일반적인 오류 원인
7. 실제 적용 사례
고객 지원 (Customer Support)
에이전트에 가장 적합한 분야:
- 대화 흐름 + 도구 통합의 자연스러운 조합
- 외부 데이터 접근 및 프로그래매틱 액션 (환불, 티켓 생성 등)
- 측정 가능한 성공 기준
- 일부 기업은 성공적 해결 시에만 과금하는 사용량 기반 가격 정책
코딩 에이전트 (Coding Agents)
높은 효과성의 이유:
- 코드 솔루션이 자동으로 테스트 가능
- 테스트 결과를 사용해 반복 개선
- 문제 공간이 잘 정의됨
- 출력 품질이 객관적으로 측정 가능
SWE-bench Verified에서 실제 GitHub 이슈 해결, 단 사람의 리뷰는 여전히 필수
8. 에이전트 구현 3대 원칙
┌─────────────────────────────────────────────────────────────────┐
│ 에이전트 구현 3대 원칙 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌───────────────┐ │
│ │ 1. 단순함 │ 에이전트 설계를 단순하게 유지 │
│ │ (Simplicity) │ │
│ └───────────────┘ │
│ │
│ ┌───────────────┐ │
│ │ 2. 투명성 │ 에이전트의 계획 단계를 명시적으로 표시 │
│ │(Transparency) │ │
│ └───────────────┘ │
│ │
│ ┌───────────────┐ │
│ │ 3. ACI 집중 │ 도구 문서화와 테스트에 신중하게 투자 │
│ │ (ACI Focus) │ Agent-Computer Interface │
│ └───────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘
요약
핵심 메시지
"LLM 영역에서의 성공은 가장 정교한 시스템을 구축하는 것이 아닙니다. 필요에 맞는 올바른 시스템을 구축하는 것입니다."
권장 경로
- 단순하게 시작: 단일 LLM 호출 최적화부터
- 철저히 최적화: 검색, 인컨텍스트 예제 활용
- 필요시 복잡성 추가: 단순한 솔루션이 명확히 부족할 때만 에이전트 도입
5가지 워크플로우 패턴 정리
| 패턴 | 특징 | 사용 시점 |
|---|---|---|
| Prompt Chaining | 순차적 단계 | 고정된 하위 작업으로 분해 가능 |
| Routing | 입력 분류 후 분기 | 입력 유형별 전문 처리 필요 |
| Parallelization | 동시 실행 | 독립적 작업 병렬 처리 |
| Orchestrator-Workers | 동적 작업 분배 | 하위 작업을 미리 정의할 수 없음 |
| Evaluator-Optimizer | 반복 개선 | 명확한 평가 기준 존재 |
다음 단계
- 간단한 프롬프트 체이닝부터 직접 구현해보기
- 도구 설계 원칙을 적용한 Function Calling 실습
- LangGraph 등 프레임워크로 복잡한 에이전트 구축